





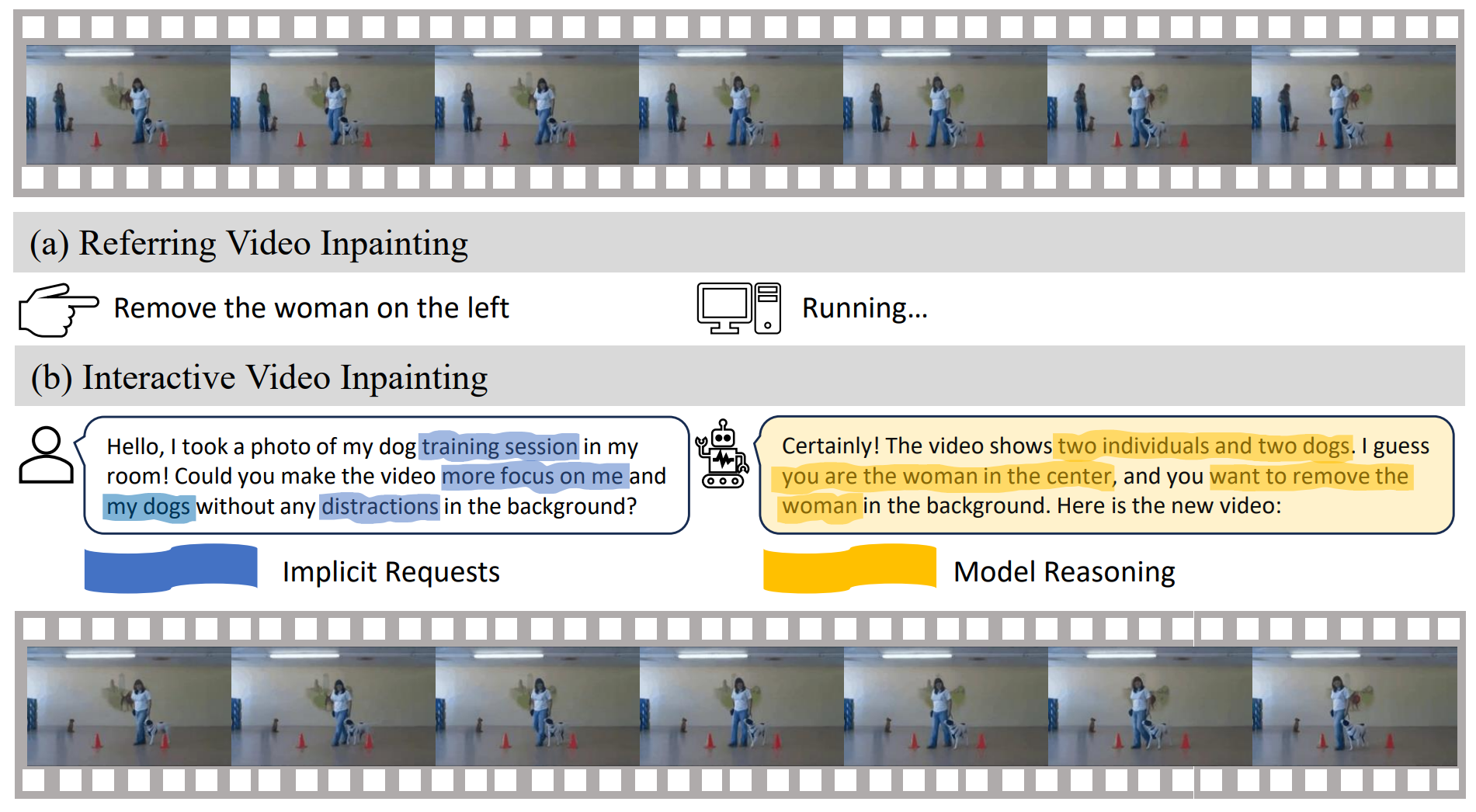

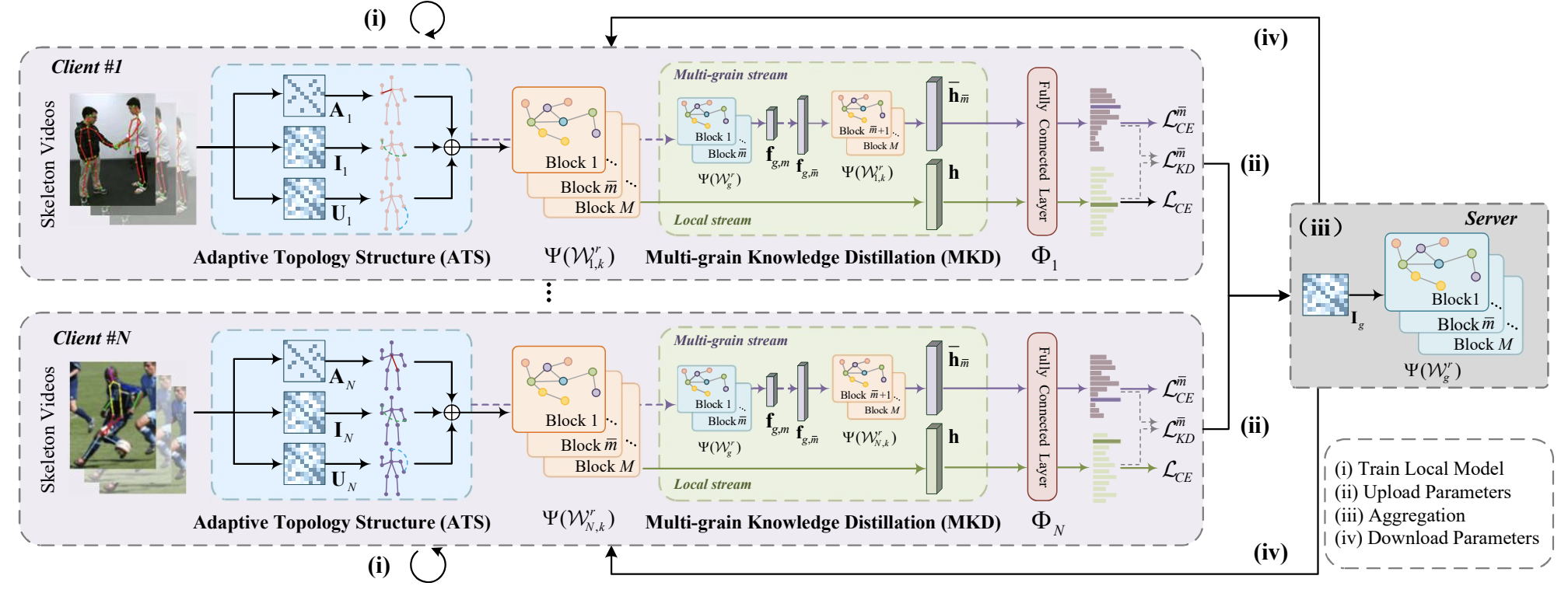
FSAR: Federated Skeleton-based Action Recognition with Adaptive Topology Structure and Knowledge Distillation
ICCV 2023
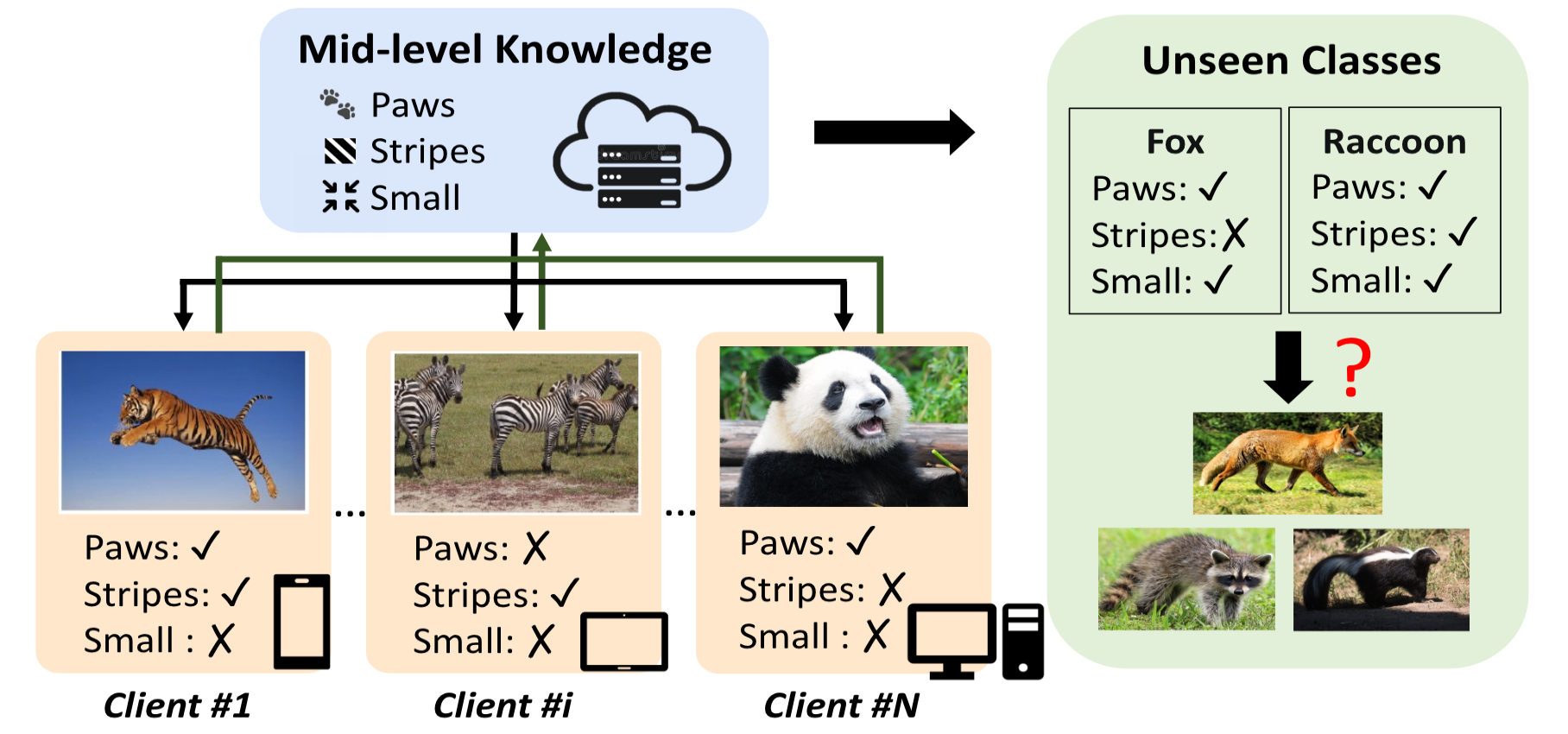
Federated Zero-Shot Learning with Mid-Level Semantic Knowledge Transfer
Pattern Recognition 2023
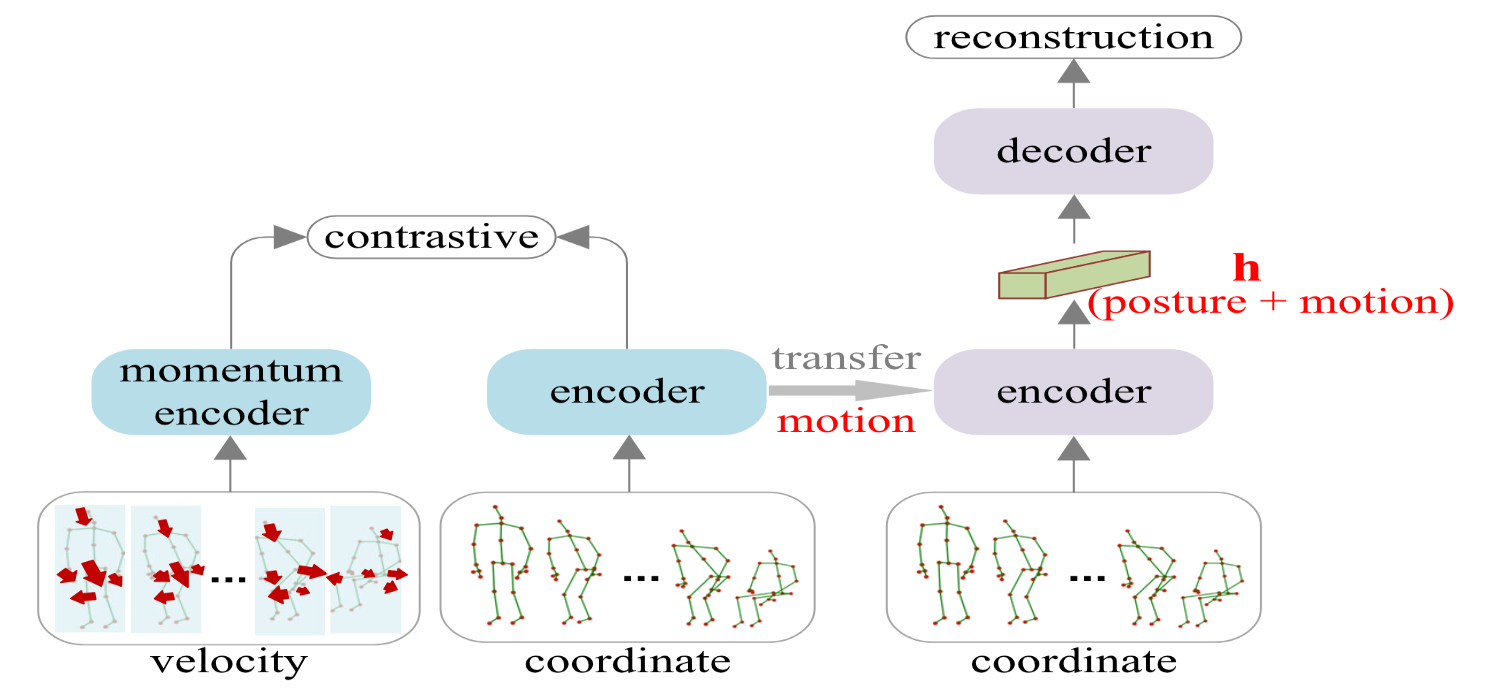
Contrast-Reconstruction Representation Learning for Self-supervised Skeleton-based Action Recognition
TIP 2022
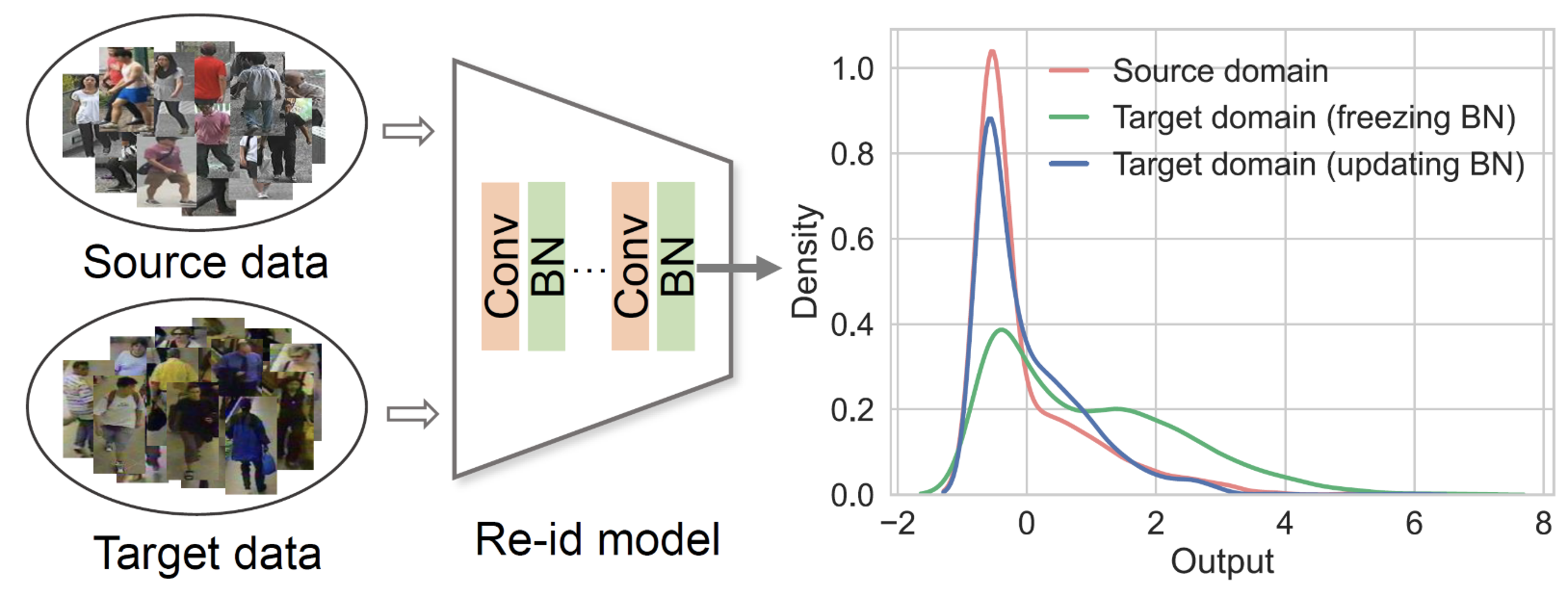
Generalizable Person Re-Identification via Self-Supervised Batch Norm Test-Time Adaption
AAAI 2022
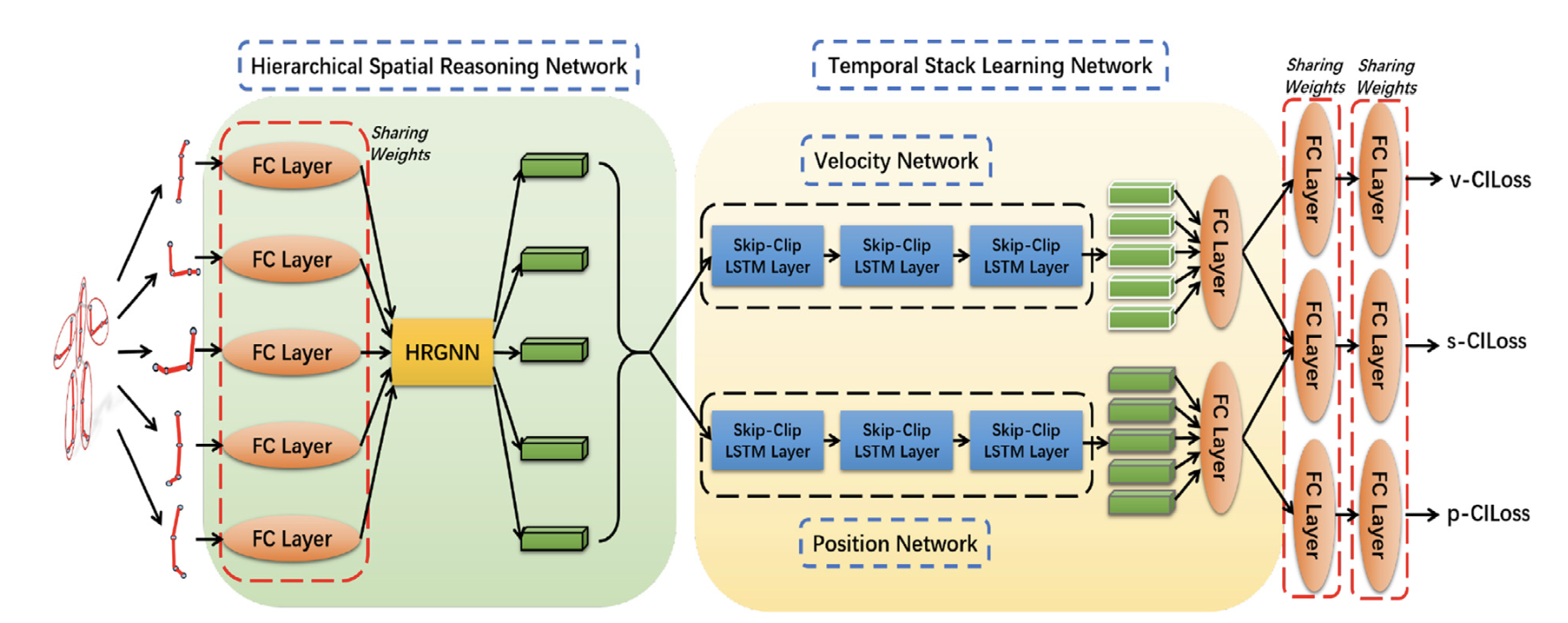
Skeleton-Based Action Recognition with Hierarchical Spatial Reasoning and Temporal Stack Learning Network
Pattern Recognition 2020
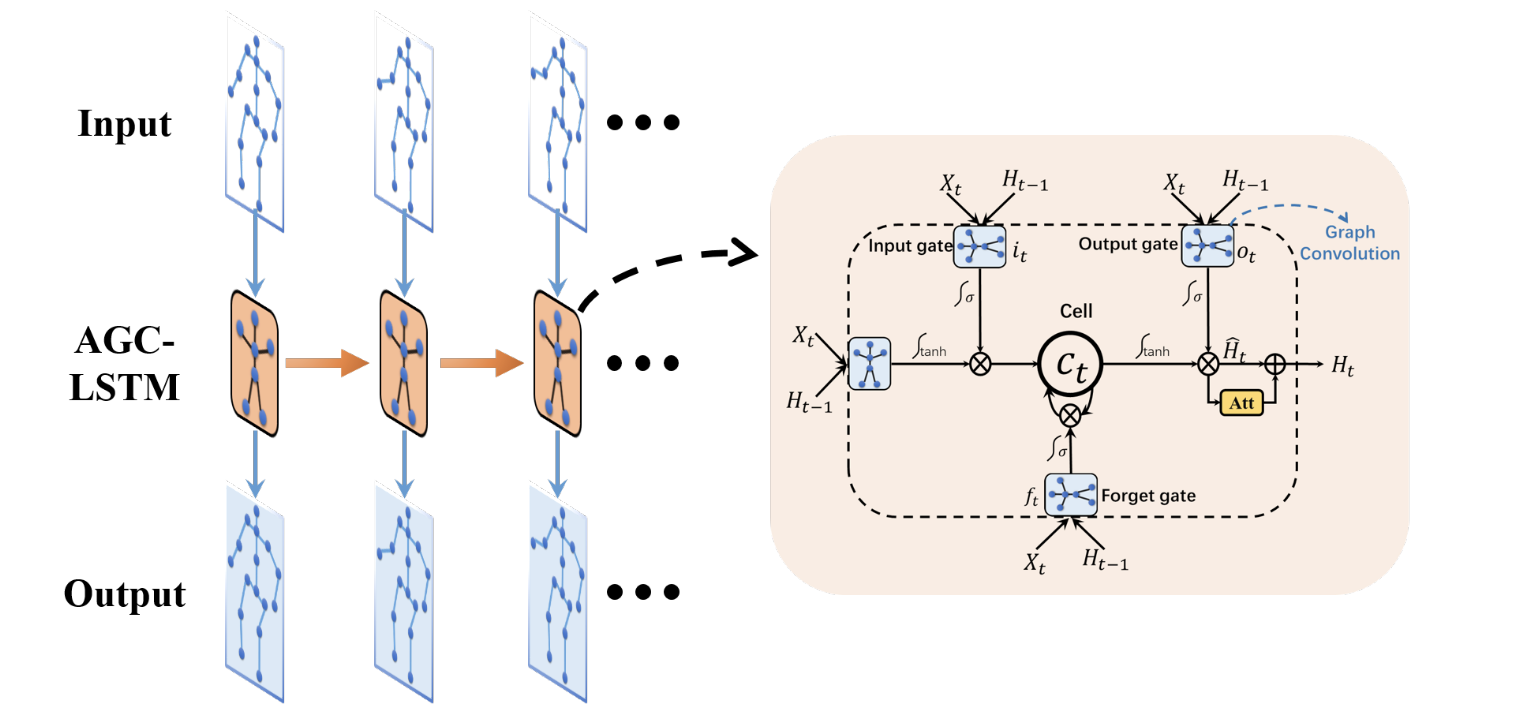
An Attention Enhanced Graph Convolutional LSTM Network for Skeleton-Based Action Recognition
CVPR 2019